Contents
#imports
import xarray as xr
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from cesm import cesm_analyze as ca
from cesm import cesm_summarize as cs
import cartopy.crs as ccrs
import cartopy.feature as cfeature
import shelve
with shelve.open('../analysis_data/descriptors') as db:
vardict = db['vardict']
modeldict = db['modeldict']
#Opening each of the Xarray datasets
ds = ca.dictorize(
func = xr.open_zarr,
modeldict = {k: v['code'] for k, v in modeldict.items()},
)
print(f'Available datasets: {list(ds)}')
#Creating var names for each dataset
hist = ds['hist']
sp1 = ds['sp1']
sp2 = ds['sp2']
sp3 = ds['sp3']
sp5 = ds['sp5']
Available datasets: ['hist', 'sp1', 'sp2', 'sp3', 'sp5']
baseline = (
ds['hist']
.sel(time=slice('1850', '1980'))
.mean('time')
)
ds_diffs = ds.copy()
ds_diffs['hist'] = baseline
ds_diffs = ca.dictorize(
func = 'diff',
modeldict = ca.nest_dicts(
ds_diffs,
),
)
USA = ca.dictorize(
func = 'sel',
modeldict = ca.nest_dicts(
ds_diffs,
{'args': {'time': '2100',
'lat': slice(0, 70),
'lon': slice(225,300)}},
),
)
USA = ca.dictorize(
func = 'agg',
modeldict = ca.nest_dicts(
USA,
{'grps': 'time.year', 'aggfunc': np.nanmean, 'roll': {}},
),
)
def plot_diff(d, var, crs, vardict, modeldict):
"""
.
"""
for k in d.keys():
d[k][k] = d[k][var].copy()
# ds = xr.combine_by_coords([d[k][k] for k in d.keys()])
models = np.array(list(d))
model_data = np.vstack(tuple([d[k][var].values for k in models]))
ds = xr.Dataset(
data_vars = {
k: (['model', 'lat', 'lon'], model_data)
},
coords = {
'model': models,
'lat': d[models[0]]['lat'],
'lon': d[models[0]]['lon'],
}
)
ds = ds.rename({models[-1]: var})
dplot = ds[var].plot(
col='model',
col_wrap=2,
transform=crs,
figsize=(10, 10),
# cmap='RdYlBu_r', vmin=-30, vmax=30, extend='neither',
cbar_kwargs={
"orientation": "horizontal",
#'anchor': (0, 2),
# "shrink": 0.8,
"aspect": 20,
'label': vardict[var]['name']+' '+vardict[var]['units'],
# 'ticks': [-35, 0, 35],
'pad': 0.1,
'spacing': 'proportional',
},
subplot_kws={
'projection': crs,
},
)
for i, ax in enumerate(dplot.axes.flatten()):
sc = modeldict[models[i]]['name'].split(':')[0] + r'$'
rcp = r'$' + modeldict[models[i]]['name'].split(':')[1]
ax.add_feature(cfeature.STATES.with_scale("110m"))
ax.coastlines("110m", color="k")
#ax.set_xlim(-180, 180)
ax.set_title('')
ax.annotate(
f'{sc}\n{rcp}',
(-130,10), # in lat, lon
ha='left', va='center',
color='black',
fontsize=12,
).set(
bbox={
'facecolor': 'white',
'edgecolor': 'black'
}
)
plt.suptitle(
f"{vardict[var]['name']} in {len(models)} climate models (NCAR CESM2)\n",
fontsize=20,
ha='center', va='center',
#x=0.5, y=0.9,
)
return dplot
#need to title each subplot
crs = ccrs.PlateCarree()
plot_diff(USA, 'tas', crs, vardict, modeldict)
plt.savefig('../figures/USA_TAS_models.png')
tas_sum = cs.average_and_max(USA, 'tas')
tas_sum.to_csv('../analysis_data/usa_tas.csv')
tas_sum
| sp1 | sp2 | sp3 | sp5 | |
|---|---|---|---|---|
| Mean | 2.908863 | 4.06936 | 5.781023 | 7.83742 |
| Max | 5.815333 | 8.140252 | 12.699799 | 18.631414 |
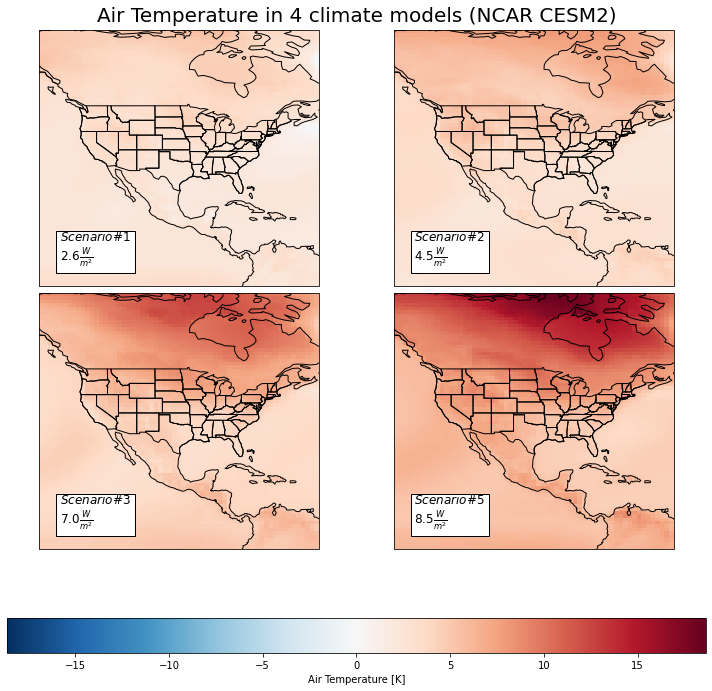
Here we have the difference between the historical average Near-Surface Air Temperature (K) and four different model predictions for the year 2100 in the North America region. The lighter regions represent less change in surface air temperature, and vice versa for the darker. We can see that the more northern areas seem to have greater predicted change. This could be due to those regions initally having more snow and ice, which when melted will result in substantially less reflection of incoming sunlight/heat. This process results in this visably larger difference in temperature than the other regions. In general, we expect increases in surface air temperature across North America, which will result in worsening wildfires, wind patterns, droughts, and more.
cs.average_and_max(USA, 'pr')
plot_diff(USA, 'pr', crs, vardict, modeldict)
plt.savefig('../figures/USA_PR_models.png')
pr_sum = cs.average_and_max(USA, 'pr')
pr_sum.to_csv('../analysis_data/usa_pr.csv')
pr_sum
| sp1 | sp2 | sp3 | sp5 | |
|---|---|---|---|---|
| Mean | 0.0 | 0.000001 | 0.000002 | 0.000004 |
| Max | 0.000061 | 0.000036 | 0.000056 | 0.0001 |
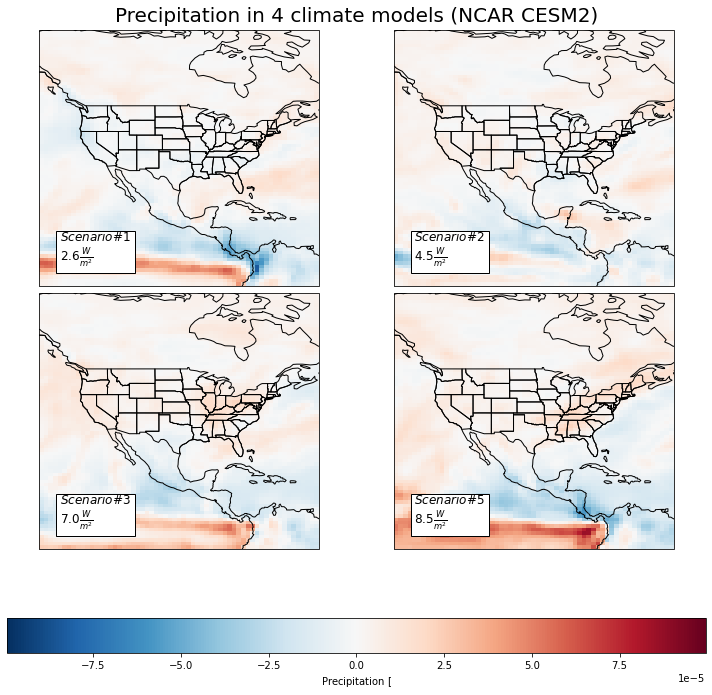
Here we have the four model predictions in 2100 for Precipitation \([\frac{kg}{m^{2}s}]\) levels in the North American region. There are a couple of interesting patterns to address here. In the first, or ‘best case’, model we can see that many of the South Western regions of the United States can expect a decrease in precipitation. However, in the other three models we can increasingly see a prediction of increased precipitation. This could be due many things, of which may include a phenomenon known as evapotranspiration where the increase in heat will lead to more water being evaporated out of trees, crops, and the ground. These patterns may also be due to stronger El nino events. For all the models, Canada appears to have a steady and slight increase in precipitation while the more Southern part of North America such as Mexico can expect a gradual decrease in precipitation.
There is a very noticable red band on the equator that grows drastically darker with the severity of model. The Intertropical Convergence Zone is the region that circles the Earth, near the equator, where the trade winds of the Northern and Southern Hemispheres come together. The intense sun and warm water of the equator heats the air in the ITCZ, raising its humidity and making it buoyant. We can see that as the model severity increases, the ITCZ is drastically increasing in amount of precipitaion. This can have serious consequences for extremem weather events.
These predicitions were interesting to me because usually we associate climate change with heat and drought. However, water is not necessarily being lost, its just that the locations it is concentrated in or not become more extreme.
plot_diff(USA, 'huss', crs, vardict, modeldict)
cs.average_and_max(USA, 'huss')
plt.savefig('../figures/USA_huss_models.png')
huss_sum = cs.average_and_max(USA, 'huss')
huss_sum.to_csv('../analysis_data/usa_huss.csv')
huss_sum
| sp1 | sp2 | sp3 | sp5 | |
|---|---|---|---|---|
| Mean | 0.001608 | 0.002107 | 0.003072 | 0.004313 |
| Max | 0.003679 | 0.003826 | 0.006504 | 0.008089 |
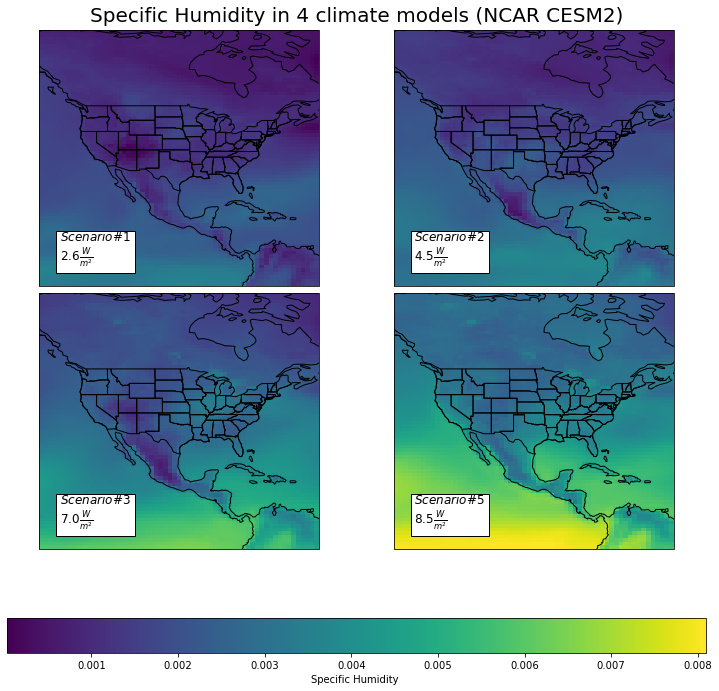
This set of plot shows us model predictions in 2100 for Specific Humidity, which is the mass of water vapor per unit mass of air. Many of the humidity trends seen here can be related to the previously discussed precipitation predictions. Just like we saw an increase in precipitation at the Intertropical Convergence Zone, we can also see a drastic increase in the humidity for this area. The general increase in humidity across North America could be due to evapotranspiration amongst other natural phenomenons.