Predicting Algerian Forest Fires
Contents
Predicting Algerian Forest Fires¶
Models¶
We build a random forest model and a logistic regression model to predict the occurence forest fires. We then compare the results.
import os
import joblib
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import dataframe_image as dfi
from tools import utils
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.metrics import precision_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import plot_roc_curve
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
import warnings
warnings.filterwarnings('ignore')
# Load and further clean data
data = pd.read_csv("data/Algerian_forest_fires_dataset_CLEANED.csv")
Random Forest Model¶
Intro¶
Given the size of the dataset (\(243 \times 15\)), building a random forest would probably be an overkill. Nontheless, we are just curious how the performance would differ when compared to the Logistic Regression model.
Because random forest is based on bootstrap aggregating decision trees, we don’t need to check any statistical features on our data since we are not making any mathematical assumptions. The only thing that need to be done further on the data is to encode all the categorical variables. The Random Forest Classifier in sklearn cannot recognize string typed categorical variables in default, thus we need to encode them into \({0,1}\) integers.
Process Data¶
Given that our dataset is small, we decided to reserve \(1/3\) of the data as testing. We don’t want to reserve too much, otherwise random forest might perform badly on a very small traning dataset. This is because bootstrap sampling on small datasets might result in many repeated samples.
# Process data into data matrix and output vector
X_rf, y_rf = utils.preprocess_data(data, ["Classes"])
# Train test split: 1/3 test, 2/3 train
X_train_rf, X_test_rf, y_train_rf, y_test_rf = train_test_split(X_rf, y_rf, test_size=0.33, random_state=42)
# Display data frame
X_train_rf.head()
| day | month | year | Temperature | RH | Ws | Rain | FFMC | DMC | DC | ISI | BUI | FWI | Region | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 226 | 14 | 9 | 2012 | 28 | 81 | 15 | 0.0 | 84.6 | 12.6 | 41.5 | 4.3 | 14.3 | 5.7 | 1 |
| 65 | 5 | 8 | 2012 | 34 | 65 | 13 | 0.0 | 86.8 | 11.1 | 29.7 | 5.2 | 11.5 | 6.1 | 0 |
| 168 | 18 | 7 | 2012 | 33 | 68 | 15 | 0.0 | 86.1 | 23.9 | 51.6 | 5.2 | 23.9 | 9.1 | 1 |
| 206 | 25 | 8 | 2012 | 34 | 40 | 18 | 0.0 | 92.1 | 56.3 | 157.5 | 14.3 | 59.5 | 31.1 | 1 |
| 144 | 23 | 6 | 2012 | 33 | 59 | 16 | 0.8 | 74.2 | 7.0 | 8.3 | 1.6 | 6.7 | 0.8 | 1 |
Hyperparameter Tuning¶
Perform Grid Search Cross Validation on the random forest model. The algorithm search through different values for hyperparameters and perform cross validation on each combination. Given the small dataset, I decided to search through the number of trees between the range \([1,100]\) and the maximum depth between \([1,5]\). The algorithm will perform \(10\)-Fold corss validation on each combination of hyperparameters.
# Grid search cross validation
if not os.path.exists("models/random_forest_gridcv.pkl"):
# Define param_grid
param_grid = {"n_estimators": (10 ** np.linspace(0, 2, 40)).astype(int),
"max_depth": [1, 2, 3, 4, 5]}
# Define random forest model
rf_model = RandomForestClassifier(random_state=42)
# Grid search cross validation
grid = GridSearchCV(rf_model, param_grid, scoring="recall", cv=10)
grid.fit(X_train_rf, y_train_rf)
# Print best result
print(grid.best_params_, grid.best_score_)
# Save grid search model
joblib.dump(grid, 'models/random_forest_gridcv.pkl')
else:
grid = joblib.load("models/random_forest_gridcv.pkl")
print("Successfully loaded pre-trained model.")
Successfully loaded pre-trained model.
Selecting the Metric for Evaluation¶
I chose to evaluate on the recall (or true positive rate) for each model during cross validation. This is because, as a model predicting forest fires, we really don’t want to predict no fire when there is actually fire. Therefore, we want to penalize false negatives (predicting no fire wrongly). Recall does exactly this job.
# Plot CV results
cv_results = pd.DataFrame(grid.cv_results_)
fig, axs = plt.subplots(1, 2, figsize=(12,4))
sns.lineplot("param_n_estimators", "mean_test_score", data=cv_results, ax = axs[0])
sns.lineplot("param_n_estimators", "mean_test_score", data=cv_results, hue = "param_max_depth", ax = axs[1])
plt.suptitle("Random Forest Hyperparameter Tuning")
for ax in axs:
ax.set(xlabel="Number of Trees", ylabel="Mean Cross Validation Score (Recall)", ylim=(0.93, 0.99))
axs[1].legend(title="Max Tree Depth")
plt.savefig("figures/figure_5.png")
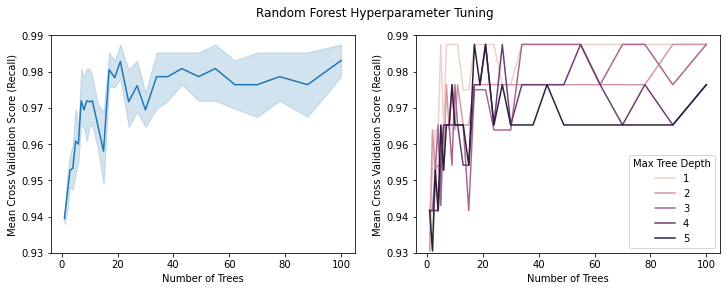
Interpretating the Result¶
The figures above display the results of cross validation. Observing the left figure we see that the cross validated recall (true positive rate) stablizes when there are more than \(35\) trees being grown. On the right figure, we see that the tree with maximum depth of one is actually the best performing model overall. We can observe that when the number of trees is larger than \(35\), the tree with depth one is consistently performing the best. Thus, based on the cross validation result, the best performing model have \(38\) trees with maximum depth of \(1\).
# Save best random forest
final_model_rf = RandomForestClassifier(n_estimators=38, max_depth=1, random_state=42)
final_model_rf.fit(X_train_rf, y_train_rf)
joblib.dump(final_model_rf, 'models/random_forest.pkl')
['models/random_forest.pkl']
Evaluating the Model¶
We evaluate the performance of the model by looking at the confusion matrix and printing the following metrics: the accuracy, the precision, and the recall.
# Output confusion matrix with test results
y_predict_rf = final_model_rf.predict(X_test_rf)
figure = utils.evaluate_model(y_predict_rf, y_test_rf)
Accuracy: 1.0
Precision: 1.0
Recall: 1.0
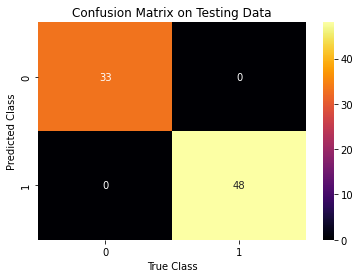
figure.savefig("figures/figure_6.png")
Further Exploration¶
By looking into our final random forest model, we see that ‘day’, ‘month’, ‘year’, ‘RH’, ‘Ws’, and ‘Region’ are never being used as a condition to perform a split. We can also see that the most important feature that the random forest based on is tne ‘ISI’ (Initial Spread Index).
# Features never used:
X_train_rf.columns[final_model_rf.feature_importances_ == 0]
Index(['day', 'month', 'year', 'RH', 'Ws', 'Region'], dtype='object')
# Most important feature
X_train_rf.columns[np.argmax(final_model_rf.feature_importances_)]
'ISI'
Logistic Regression¶
Data Preprocessing¶
We first examine the correlation matrix of the weather metrics in our dataset. We find that DMC, DC, and BUI and highly correlated with one another. To avoid multicollinearity, we remove DC and BUI from our feature set. We choose to use DMC becuase it is the least correlated with the remaining features.
# Examine correlation matrix for multicollinearity
data.iloc[:, 3:-2].corr()
| year | Temperature | RH | Ws | Rain | FFMC | DMC | DC | ISI | BUI | FWI | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| year | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Temperature | NaN | 1.000000 | -0.651400 | -0.284510 | -0.326492 | 0.676568 | 0.485687 | 0.376284 | 0.603871 | 0.459789 | 0.566670 |
| RH | NaN | -0.651400 | 1.000000 | 0.244048 | 0.222356 | -0.644873 | -0.408519 | -0.226941 | -0.686667 | -0.353841 | -0.580957 |
| Ws | NaN | -0.284510 | 0.244048 | 1.000000 | 0.171506 | -0.166548 | -0.000721 | 0.079135 | 0.008532 | 0.031438 | 0.032368 |
| Rain | NaN | -0.326492 | 0.222356 | 0.171506 | 1.000000 | -0.543906 | -0.288773 | -0.298023 | -0.347484 | -0.299852 | -0.324422 |
| FFMC | NaN | 0.676568 | -0.644873 | -0.166548 | -0.543906 | 1.000000 | 0.603608 | 0.507397 | 0.740007 | 0.592011 | 0.691132 |
| DMC | NaN | 0.485687 | -0.408519 | -0.000721 | -0.288773 | 0.603608 | 1.000000 | 0.875925 | 0.680454 | 0.982248 | 0.875864 |
| DC | NaN | 0.376284 | -0.226941 | 0.079135 | -0.298023 | 0.507397 | 0.875925 | 1.000000 | 0.508643 | 0.941988 | 0.739521 |
| ISI | NaN | 0.603871 | -0.686667 | 0.008532 | -0.347484 | 0.740007 | 0.680454 | 0.508643 | 1.000000 | 0.644093 | 0.922895 |
| BUI | NaN | 0.459789 | -0.353841 | 0.031438 | -0.299852 | 0.592011 | 0.982248 | 0.941988 | 0.644093 | 1.000000 | 0.857973 |
| FWI | NaN | 0.566670 | -0.580957 | 0.032368 | -0.324422 | 0.691132 | 0.875864 | 0.739521 | 0.922895 | 0.857973 | 1.000000 |
We preprocess the data by removing the ‘year’ column because there is only one value for the entire dataset. We also remove the DC and BUI columns. We encode ‘Regions’ in the feature matrix and ‘Classes’ in the y vector to binary representations. Lastly, we normalize the weather metrics in the feature matrix.
# Process data into data matrix and output vector
X_lr, y_lr = utils.preprocess_data(data, ['Classes', 'year', 'DC', 'BUI'])
# Normalize input columns
utils.normalize(X_lr, ['Temperature', 'RH', 'Ws', 'Rain', 'FFMC', 'DMC', 'ISI', 'FWI'])
# Train test split: 1/3 test, 2/3 train
X_train_lr, X_test_lr, y_train_lr, y_test_lr = train_test_split(X_lr, y_lr, test_size=0.33, random_state=42)
Modeling¶
# Create and fit logistic regression model with l2 penalty
clf = LogisticRegression(penalty='l2', random_state=42).fit(X_train_lr, y_train_lr)
Predictions and Metrics¶
We use our trained model to predict on the test set and display the confusion matrix. We calculate accuracy, precision, and recall for out model. It looks like our model does well!
# Output confusion matrix on test results
y_predict_lr = clf.predict(X_test_lr)
figure = utils.evaluate_model(y_predict_lr, y_test_lr)
Accuracy: 0.9629629629629629
Precision: 0.9583333333333334
Recall: 0.9787234042553191
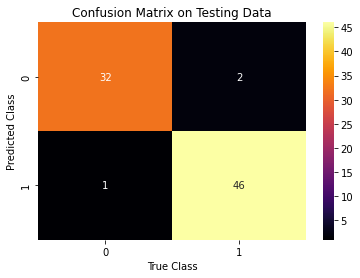
figure.savefig('figures/figure_7.png')
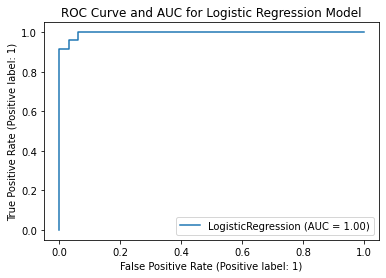
To better evaluate our model, we examine the ROC curve. The area under the curve is close to 1, which is desired.
# Show roc curve
plot_roc_curve(clf, X_test_lr, y_test_lr);
plt.title("ROC Curve and AUC for Logistic Regression Model")
plt.savefig('figures/figure_8.png')
Interpreting the Result¶
A simple logistic regression model achieves astounding accuracy on the test set. It is possible that the data is inherently well-conditioned and that Algerian forest fires have particularly distinct features that set them apart from regular weather conditions. It is unclear how the model will respond to forest fires in other locations. Further exploration can be done by applying our model to areas with similar climates and monitoring the model’s variance. A question to ponder is: Are Algerian forest fires easier to predict than other forest fires?
Comparing the Results¶
Both models have impressive test accuracy, for reasons explored earlier. However we do see that the random forest slightly outperforms the logistic model, achieving perfect test accuarcy. Although the accuarcy is per haps unexpectedly high, its relative performance to the logistic model is not surprising considering that random forests are in general more powerful architectures than logistic regression. The removal of the DC and BUI variables for the logistic model should not impact performance, as these are calculated from other variables in the data.
# Compute accuracy, precision, and recall from both models and output in dataframe for comparison
rf_accuracy = accuracy_score(y_test_rf, y_predict_rf)
rf_precision = precision_score(y_test_rf, y_predict_rf)
rf_recall = recall_score(y_test_rf, y_predict_rf)
lr_accuracy = accuracy_score(y_test_lr, y_predict_lr)
lr_precision = precision_score(y_test_lr, y_predict_lr)
lr_recall = recall_score(y_test_lr, y_predict_lr)
comparison = pd.DataFrame(data = {"Model": ["Random Forest", "Logistic Regression"], "Accuracy": [rf_accuracy, lr_accuracy],
"Precision": [rf_precision, lr_precision], "Recall": [rf_recall, lr_recall]})
# Save model comparison dataframe as image
dfi.export(comparison, "figures/figure_9.png")
comparison
[0512/034422.837116:ERROR:bus.cc(397)] Failed to connect to the bus: Failed to connect to socket /var/run/dbus/system_bus_socket: No such file or directory
[0512/034422.837281:ERROR:bus.cc(397)] Failed to connect to the bus: Failed to connect to socket /var/run/dbus/system_bus_socket: No such file or directory
[0512/034422.841921:ERROR:zygote_host_impl_linux.cc(263)] Failed to adjust OOM score of renderer with pid 774: Permission denied (13)
[0512/034422.846068:WARNING:bluez_dbus_manager.cc(248)] Floss manager not present, cannot set Floss enable/disable.
[0512/034422.860251:ERROR:zygote_host_impl_linux.cc(263)] Failed to adjust OOM score of renderer with pid 776: Permission denied (13)
[0512/034422.899603:ERROR:sandbox_linux.cc(377)] InitializeSandbox() called with multiple threads in process gpu-process.
[0512/034423.171208:INFO:headless_shell.cc(659)] Written to file /tmp/tmphhhzpekv/temp.png.
| Model | Accuracy | Precision | Recall | |
|---|---|---|---|---|
| 0 | Random Forest | 1.000000 | 1.000000 | 1.000000 |
| 1 | Logistic Regression | 0.962963 | 0.978723 | 0.958333 |
We can further examine the importances of each feature in prediction by looking at the coefficients from our logistic regression model. As seen below, the FFMC was the most powerful in prediction (we can compare directly since we normalized the data). This makes sense based on our EDA which showed that FFMC combines aspects of many of the other features and is therefore the most holistic predictor of fires. In fact, this means that an increase of 1 point in FFMC increases the odds of a forest fire by about 10%, which is quite considerable. Fire scientists can use FFMC as a north star metric in understanding fire probabilities.
# Display sorted coefficients for features in the logistic regression model
feature_importances = pd.DataFrame(data = {"Feature": X_train_lr.columns, "Coefficient": clf.coef_[0]}).sort_values("Coefficient", ascending = False)
# Save feature importances dataframe as image
dfi.export(feature_importances, "figures/figure_10.png")
feature_importances
[0512/034423.487118:ERROR:bus.cc(397)] Failed to connect to the bus: Failed to connect to socket /var/run/dbus/system_bus_socket: No such file or directory
[0512/034423.487275:ERROR:bus.cc(397)] Failed to connect to the bus: Failed to connect to socket /var/run/dbus/system_bus_socket: No such file or directory
[0512/034423.489539:WARNING:bluez_dbus_manager.cc(248)] Floss manager not present, cannot set Floss enable/disable.
[0512/034423.489694:ERROR:zygote_host_impl_linux.cc(263)] Failed to adjust OOM score of renderer with pid 838: Permission denied (13)
[0512/034423.496253:ERROR:zygote_host_impl_linux.cc(263)] Failed to adjust OOM score of renderer with pid 840: Permission denied (13)
[0512/034423.511189:ERROR:sandbox_linux.cc(377)] InitializeSandbox() called with multiple threads in process gpu-process.
[0512/034423.734788:INFO:headless_shell.cc(659)] Written to file /tmp/tmpufj083nk/temp.png.
| Feature | Coefficient | |
|---|---|---|
| 6 | FFMC | 2.315579 |
| 8 | ISI | 2.162191 |
| 9 | FWI | 1.837229 |
| 7 | DMC | 0.343307 |
| 5 | Rain | 0.216683 |
| 1 | month | 0.148903 |
| 10 | Region | 0.116011 |
| 2 | Temperature | 0.099857 |
| 3 | RH | 0.084562 |
| 4 | Ws | 0.031104 |
| 0 | day | -0.001194 |